There is no ‘Nice’ Web. Yet
As communities fight for healthier, more resilient ways to discover, share, and create online, Bri Griffin questions the existence of a better internet.

There is no ‘nice’ web
Thirty-six years after the Hypertext Transfer Protocol first linked networks of distant CERN researchers, the web is used by nearly 70% of the global population. A default narrative traces the idea of ‘freedom’ from ARPANET — the first public computer network — to the modern definition of ‘The Internet’ as being “in the service of late capitalist, decentralized control” — as Lori Emerson, Media Archeology Lab’s founding director argues.
In the book From Counterculture to Cyberculture, Stanford Professor Fred Turner dives into a western-focused, ‘liberatory’ history of computing, pointing out how iconic countercultural publications like People’s Computer Company (PCC) and Whole Earth Catalog were based just a few blocks from human-computer interaction engineers at Stanford. In 1972, leading up to the era of personal computing, PCC declared: “Computers are mostly used against people instead of for people; used to control people instead of to free them; Time to change all that.” Yet, under this same umbrella of ‘access’ and ‘user-friendly,’ infinite potentials for internetworking shifted rapidly to a set of limitations defined by a handful of corporations.
Modern computing has never escaped its military origins: The networked technologies we use enable mechanisms of control such as legal persecution, mass surveillance, censorship, discrimination, addiction, and distraction; Most internet traffic is routed through websites that work in exchange for tracking and selling personal data: You must subscribe, share your location, and disable adblockers, in order to experience the illusion of a public sphere. Instead, these environments are morphed via platforms that, according to the MIT Digital Currency Initiative , are “unelected, unaccountable, and often impossible to audit or oversee,” and which have invested billions of dollars into creating easy experiences that predict and direct people’s behavior. By showing users ‘recommended’ and viral content, these artificial echo chambers of culture spur aesthetics and behaviors to spread globally. Ever heard of UK children showing up to school with an American accent because they’ve binge-watched too much YouTube during the pandemic?

Eugenio Dittborn, Airmail Painting N. 71, ‘The 6th History of the Human Face (Black and Red Camino)‘, 1989 (detail).
We have instant access to petabytes of data. However, our ‘access’ depends on internet infrastructures existing alongside stable energy sources and caches of electronic devices, all of which must meet specific hardware and software requirements. Data must then be consistently hosted online and made discoverable. You must spend time and money to learn each platform’s rules, optimize your content for search engines and algorithms, survive structural and technical updates, pay for server/hosting costs, and catch domain renewal notices. Governing bodies, including internet service providers, then filter and modify incoming data, based on who you are and where you live. In 2011 — responding to the Occupy Wall Street movement — it became impossible in China to search the word ‘Occupy’ followed by a city’s name. More recently, as of February 2025, 8000 government web pages in the US were deleted for having ‘diversity initiatives’ or ‘promoting gender ideology.’
Shutting off internet access entirely has been a common practice during times of political unrest — as it’s been the case in Egypt, China, and Myanmar. Access to information is tied to power; Virality and persistence are interlocked with influence and control.
As generative chatbots like ChatGPT provide information isolated from the numerous voices of its sources, traditional models of public consensus formation relying on open dialogue and debate disappear.
Although not easily traceable, actions (intaking information) have reactions (outputting information) that “traverse among and between networks” both online and IRL. Mega-platforms involve an infinite content feed fueled by humans (and bots) who master the art of virality, manufacture trends, and influence global markets.
However only a few actual people are responsible for what we doom-scroll. The phenomenon of participation inequality was first recognized in 1992 as researchers analyzed who helped to write collaborative digital documents. Later, Danish computer scientist and researcher Jakob Nielson applied this concept to the web with his Rule of Participation Inequality, claiming that content online is typically created by “the same 1% who almost certainly differ from the 90% you never hear from.” Believers of the dead internet theory fear that bots are responsible for creating most of the content online. Everything we need seems to be available in one place, flowing across user-generated worlds optimized to capture our attention.

An Instagram crop of an image found on a meme account on Reddit called @mood._.quotes. Their bio says “steal whatever you feel is relatable!”
In the context of this dynamic between creation and consumption, I can’t help but think of Jodi Dean’s description of communication online, in the essay Communicative Capitalism:
“...a message is no longer primarily a message from a sender to a receiver. Uncoupled from contexts of action and application — as on the web or in print and broadcast media — the message is simply part of a circulating data stream. Its particular content is irrelevant. Who sent it is irrelevant. Who receives it is irrelevant. That it needs to be responded to is irrelevant. The only thing that is relevant is circulation, the addition to the pool.”
Physical connections to data centers, subsea cables, and cloud providers are at the heart of this primarily meaningless circulation. Many of us cannot process what they’ve been exposed to online, or even remember the photos they’ve uploaded to their iCloud. We don’t know what’s real, or if the profiles we interact with belong to actual people or not. Life online has transitioned from memetic warfare and shadowbanning to algorithmically propelled propaganda and violence. Today, the web is an overwhelming pool of media and platforms; Their terms of use, content, and culture have become our society’s default design. The web has never been evenly distributed, but it continues to alter the existence of all living creatures — including those incapable of visiting a website. If there is a ‘good web,’ few have access to it.
Finding a better internet
On February 18, 2021, I started an are.na board titled “nice web.” Are.na served as a record for my surfing sessions and as a public bookmarking system, accepting any link from the web as a contribution to its almost pinterest-like boards. Other people might peek into my collections of links (PDFs, websites, social media posts, and images) and add it to one of their personal archives. I enjoy noticing the gentle movements of information traversing across boards, and the voyeuristic feeling built into exploring such an intimate platform. Despite containing a massive amount of data — and, by design, encouraging discovery and connection of information — are.na still feels extremely slow, quiet, and private, like your own secret room. Compared to other social media, here your work resonates much longer in time: Someone might easily discover a screenshot you posted and add it to their own research board many years later.
Discovery is not possible without lists and links.
Diving into the web’s history reveals increasingly technical methods for discovery. In a pre-social media era, casual internet users needed the help of people who knew how to dig for the ‘good stuff.’ When Srinija Srinivasan, Yahoo’s fifth employee, started working at the company, she immediately hired a team of skilled ‘web surfers.’ Their lists and directories were key to Yahoo’s initial success because most people still had few entry points into the web: “We’ve done the work for you — we’ve gone through the web and these are the best sites,” Dave Sikula, a longtime Yahoo surfer, pointed out at the time. Categorization systems are the web’s backbone. The internet early users experienced was contained within a list of user-created links.
The expression ‘surfing the internet’ was first coined in 1992 by the librarian and ‘Net-mom’ Jean Armor Polly. In 1995, she was contributing towards a growing collection of ‘internet directories,‘ physical encyclopedias of internet resources with organized lists of URLs. Discovering new websites was then supported by webrings, groups of people gathering over similar topics and exchanging links to each other’s sites. In 1999, The New York Times compared “internet surfing using a webring” to “sharing a cup of tea with a group of strangers who are batty about a favorite hobby.” Crucially, the same article suggested that there was already too much information online; As people attempted to decipher conflicting sources of truth, websites that weren’t capable of attracting advertisers were perceived as less reliable — at least according to Paul M. A. Baker, a professor who studied niche online communities.
Websites encouraging transparent cooperation, such as are.na and Wikipedia, were spun out of web surfing because, according to journalist Ernie Smith, they “reward clicking, and become more valuable the further down the rabbit hole you go.” Are.na co-founder and former NastyNets surfer Damon Zuconi describes surf clubs as “a type of collective wayfinding, or figuring out.
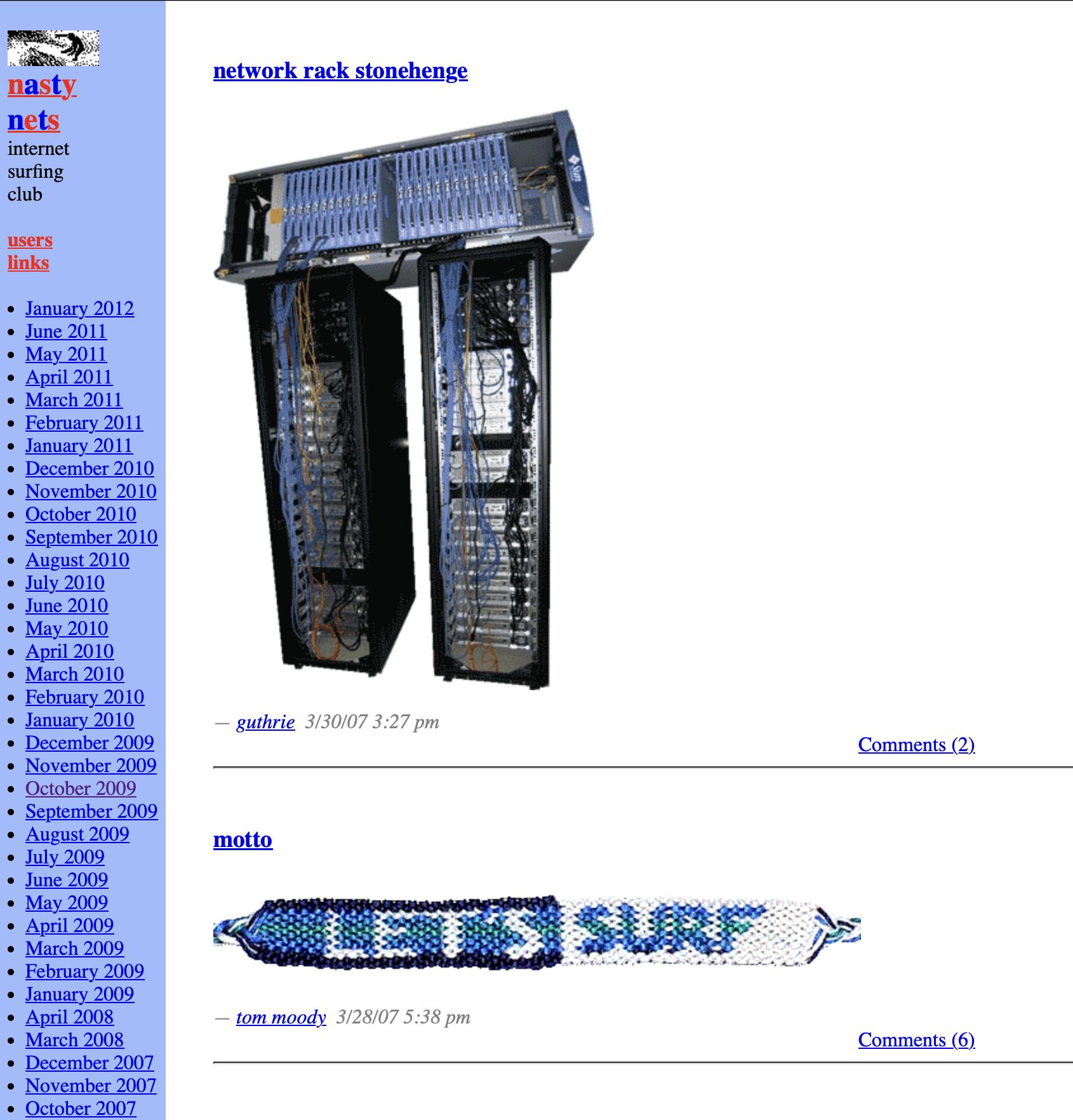
A screenshot of archived static file of the NastyNets internet surfing club, March 2007.
Today, environments where people can meet each other online and learn about the world are sealed, disconnected from the broader internet. Crucial features such as fact-checking and information verification are now left to private conglomerates like Meta whose code limits links leading outside their platforms. As generative chatbots like ChatGPT provide information isolated from the numerous voices of its sources, traditional models of public consensus formation relying on open dialogue and debate disappear.
Discovery is not possible without lists and links. Daniel Murray — an artist and advocate for The Web Revival — describes them as “the lifeblood of the web.” Tracy Durnell — a writer hosting a website on the ‘IndieWeb‘ — suggests that links reflect “the process of connecting ideas and constructing something bigger: Arguments, stories and even poems.” At the same time, lacking links’ lists might be the symptom of a greater issue, blogger Jason Velazquez argues: “Somewhere between the late 2000’s aggregator sites and the contemporary For You Page, we lost our ability to curate the web.” A loss of curation means that we have essentially relinquished our right to establish credibility and, as a result, our systems of value — as well as the type of communities we form — are shifting.
But communities flourishing outside centralized media don’t always want to be found. Slow, thoughtful pockets of lore are hidden within the dark forests of like-minded peers. Some encourage ‘hand-making’ pages out of pure HTML, using experimental protocols, offline networks, and custom-made social media apps. The Midnight Pub, for example, is a ‘slow social media’ allowing visitors to create text-based pages on its website. It describes itself as a ‘virtual speakeasy.’ The entry message recites: “This little establishment aims to become your hide-out amidst the sprawling metropolis of bits and data the internet has become.”
There are endless versions of the web for those who can find them
What we’re capable of discovering and understanding online depends on our relationship to technology. The biggest luxury, online, is context. “Technologies, just like writing, are diverse systems that have their own grammars, words, and folksonomy. A collection of attributes that are arguably, difficult, and sometimes impossible to translate,” The Convivial Society writes. Because centralized web platforms limit exposure to alternative forms of media and community, a few realities dominate collective consciousness. In theory, everyone using the web has a potential to alter the way we use it; Websites should be contributed to and maintained by anyone. But they are not.
While some advocates for a ‘better internet’ argue that we just need to become more technical, ‘being technical’ in a world of planned obsolescence is a privilege. Most users have no reason to question how they send and receive information. Expertly crafted front-ends stifle the act of challenging platforms at all. Who has the time?
We lost our ability to curate the web.
As communities fight for healthier, more resilient ways to discover, share, and create online, the World Wide Web’s inventor Tim Berners Lee says, “The future hinges on our ability to both reform the current system and create a new one that genuinely serves the best interests of humanity.” Each new technological innovation (Peer-to-peer platforms, the Wayback Machine, WordPress, and blockchain) is a potential building block for a secure ‘meta-internet.’ There’s a desire to connect all websites to each other, weave platform-specific benefits (i.e. mentions, following, etc.) into the fabric of the web, and support archives for defunct or past versions of websites. However, it’s important to note that today’s mega-platforms are built on top of the web’s already distributed and open protocols. In her blog, renowned computer science expert Lixia Zhang points out that we’ve already lost a key battle with network architecture, as we evolved from the ability to “communicate with anyone else with an IP address” to having everyone’s names and identities tied to unsecured app layers, our market has made it a business to “see every key click one makes.”
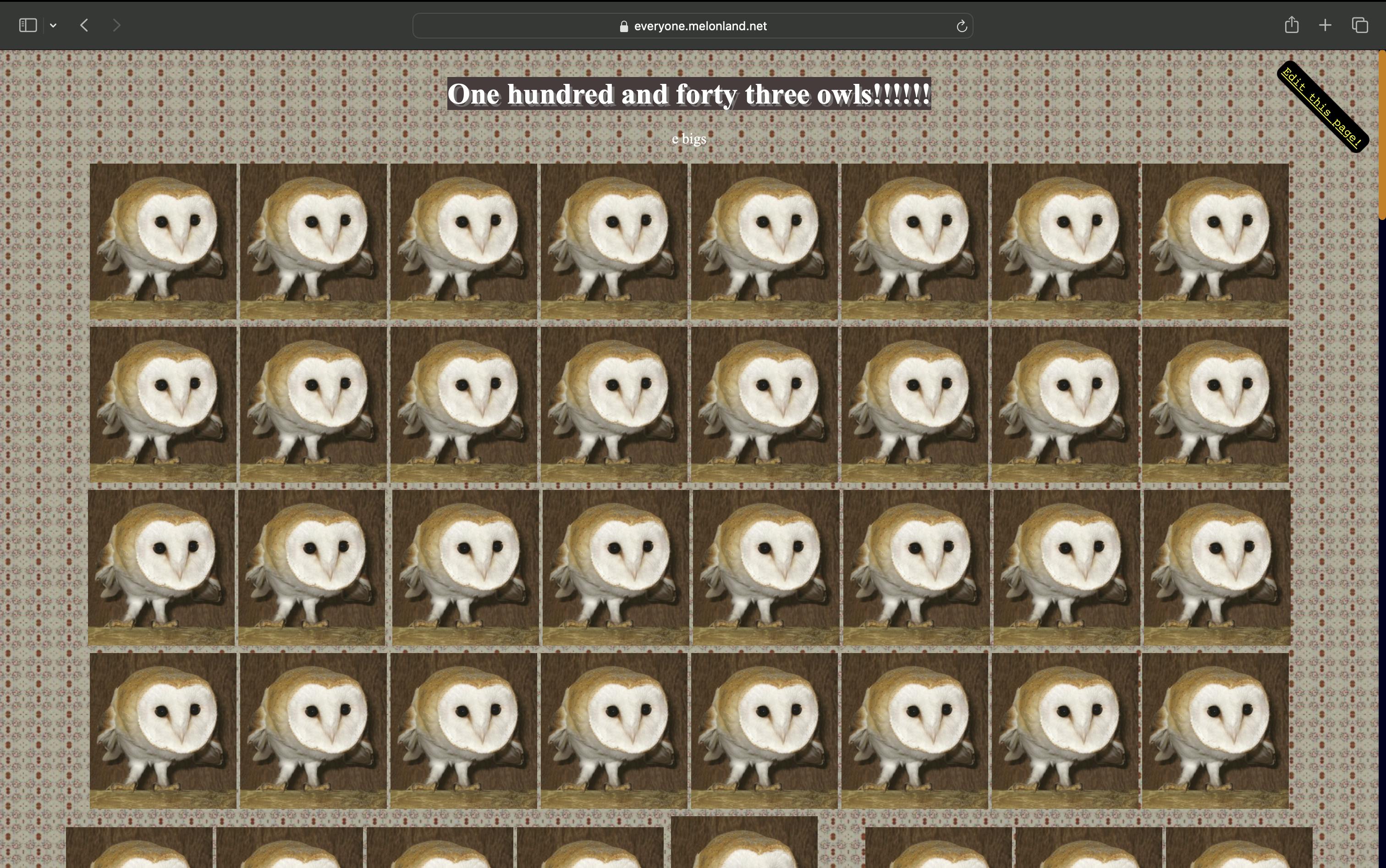
A screenshot of the 142 owls that live on everyone.melonland.net
According to Brewster Kale, who founded the non-profit Internet Archive in 1996, the way we code the web will determine how we live online. In order to change the web, he argues, we need to embed our values in it: “Freedom of expression needs to be baked into our code. Privacy should be baked into our code.” But warnings always come along with building new systems. In Christopher Alexander’s A city is not a tree, the argument for more ‘organic’ urban design reminds me of this fight for alternative layers of the web:
“Every time a city trades its humanity and richness… for a conceptual simplicity which benefits only designers, planners, administrators, and developers, so, too, does the individual lose that same depth.”
So, who gets to make the new internet?
Slow, thoughtful pockets of lore are hidden within the dark forests of like-minded peers.
“The World is Free but I am not; the space is so saturated, / the pressure of all which wants to be heard so strong / that I am no longer capable of knowing what I want”. — The Ecstasy of Communication (1987), Jean Baudrillard.
Bri Griffin is an artist, community designer, and strategist at rhizome.org focused on internet research and electronic art curation. Their work blends sculpture and sonic works with various forms of program facilitation and research, typically relating to hidden structures that shape our digital experiences. Responding to their past as an architectural experience design consultant, Bri reimagines environments (irl and virtual) that challenge conventional boundaries for a thoughtful, connected digital world.

An extremely low-res version of a Lymantriinae Moth’s photo, taken by John Horstman in 2013 with the caption ‘Angels Exist.‘
Bri Griffin is an artist, community designer, and strategist at rhizome.org focused on internet research and electronic art curation. Their work blends sculpture and sonic works with various forms of program facilitation and research, typically relating to hidden structures that shape our digital experiences. Responding to their past as an architectural experience design consultant, Bri reimagines environments (irl and virtual) that challenge conventional boundaries for a thoughtful, connected digital world.